|
Hello! I recently graduated with a Master's degree from the University of Utah, where I had the opportunity to work with Tolga Tasdizen on multimodal vision-and-language problems and medical imaging research. Prior to joining Utah, I gained valuable experience as an AI Software Engineer at Bobble AI, where I was a member of the Conversational Intelligence Team, focusing on natural language processing problems. I completed my undergraduate studies at the University of Delhi, during which time I engaged in a diverse range of research projects, including developing a Hindi dense image captioner and working on long-sequence legal text processing. I am interested in the vast real-world applications and immense research potential of Deep Learning. I enjoy talking to people and building (hopefully useful) things together :) If you want to discuss research/collaborate, feel free to send me an email! |

|
|
I have a broad interest in Deep Learning. I'm majorly interested in Vision-and-Language and Medical Imaging problems. |
|
|
|
|
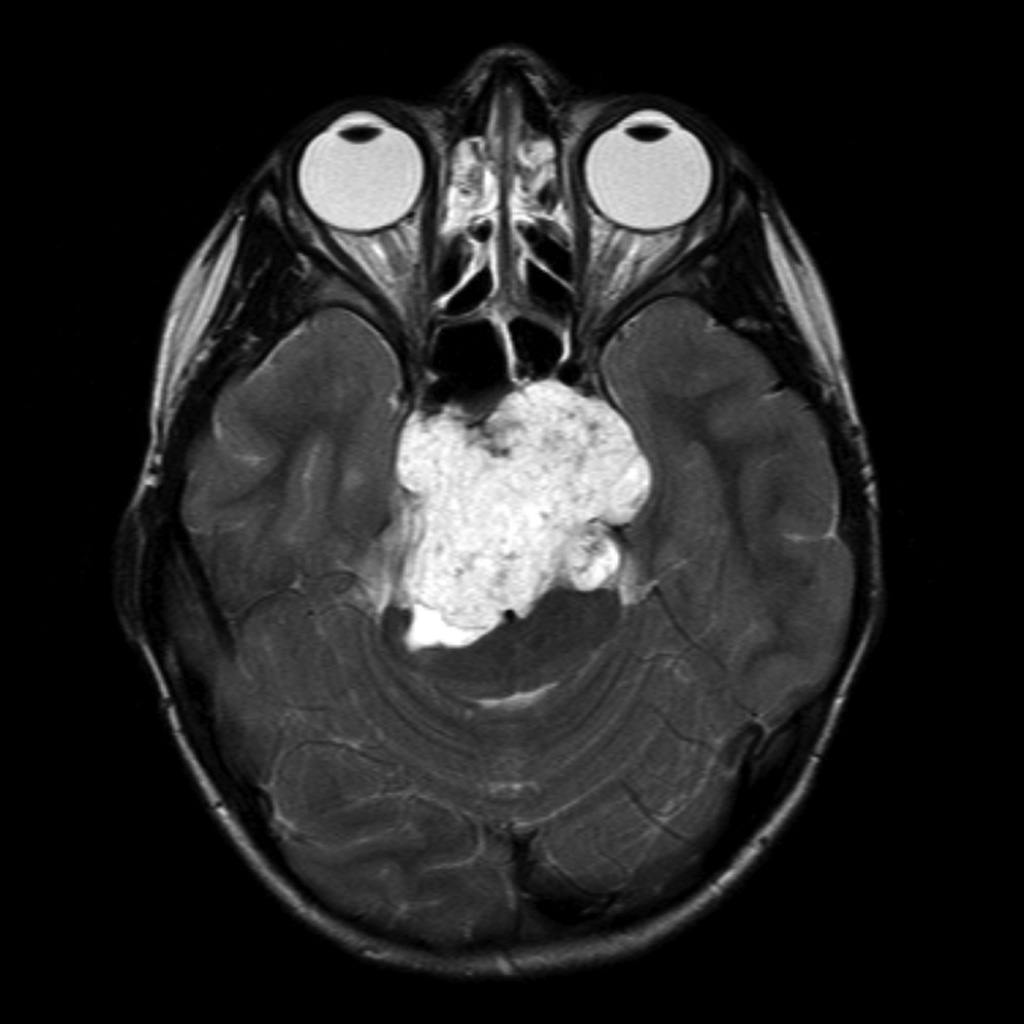
Harshit, Tyler Richards, Tolga Tasdizen This work explores the automated detection and segmentation of rare central skull base tumors using multimodal 3D CT and MRI data. We utilized a U-Net-based deep learning pipeline, specifically tailored for clinical applications, to achieve accurate segmentation. |
|
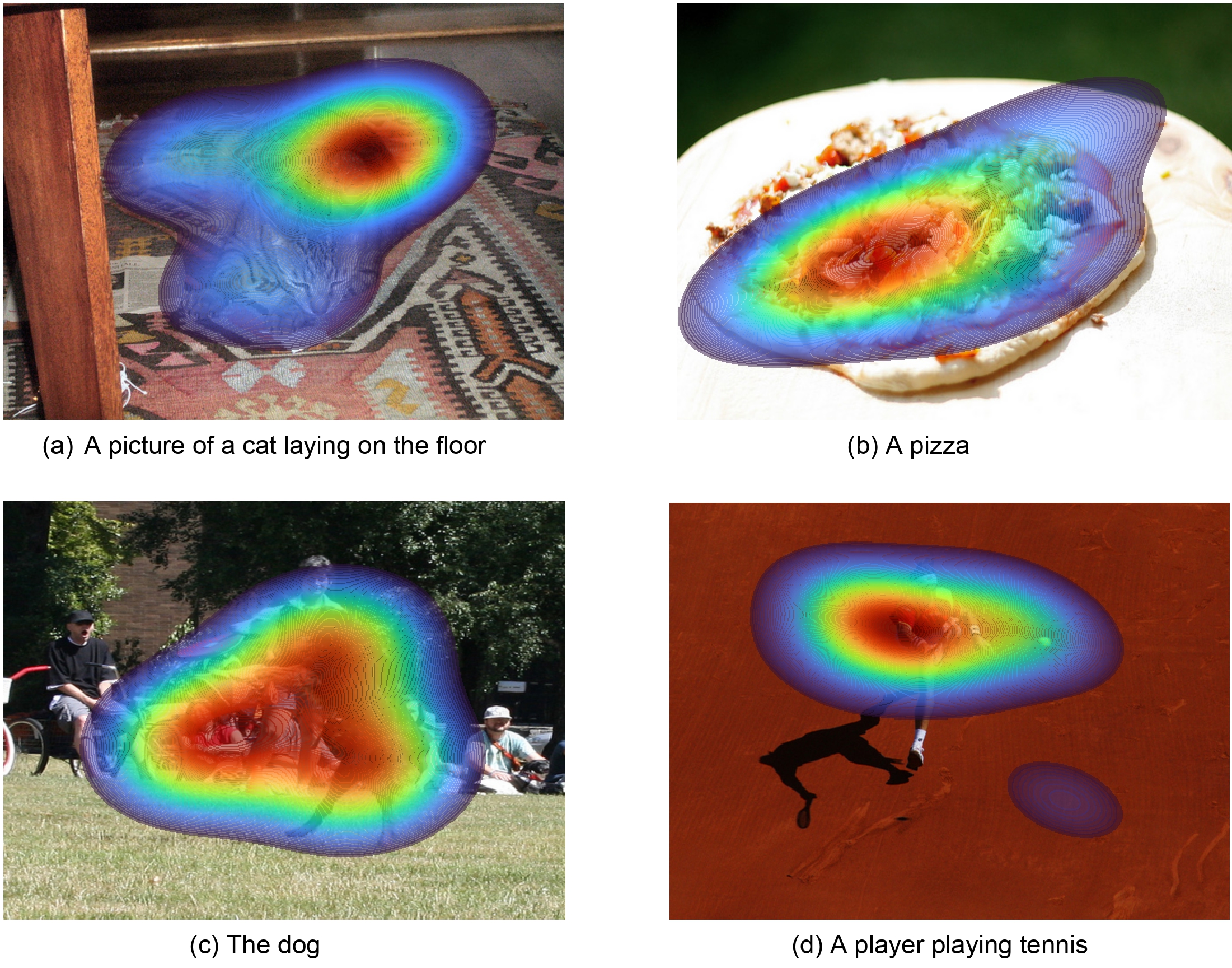
Harshit, Tolga Tasdizen VISTA introduces a human eye-tracking aligned dataset for multimodal models to enhance the transparency, interpretability, and trustworthiness of Vision and Language Models. This work bridges image regions and text segments through human visual attention data. |
|
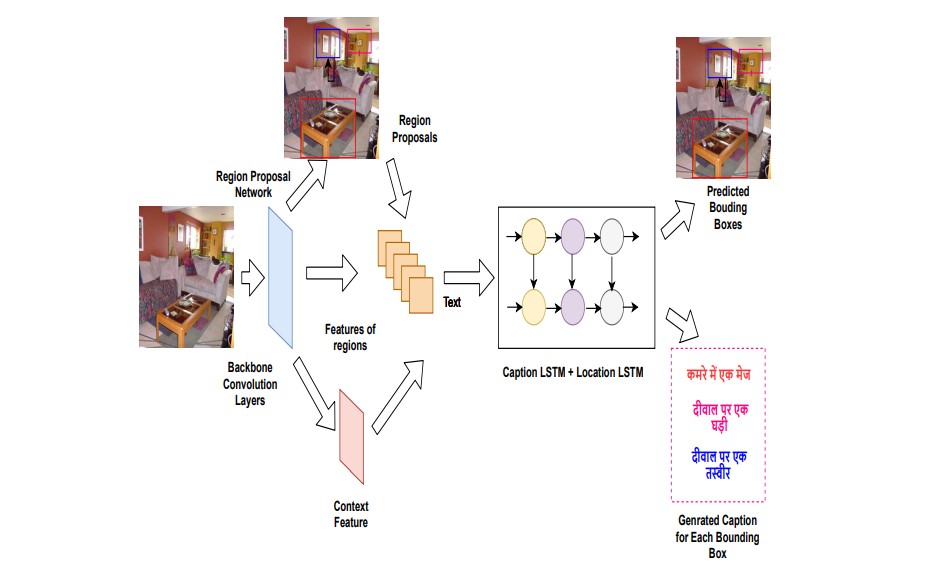
Santosh Kumar Mishra, Harshit, Sriparna Saha, Pushpak Bhattacharyya We proposed a dense image captioning model to describe different segments of an image by generating more than one caption in the Hindi language. This is the first attempt on Hindi dense image captioning. We created our own dataset by translating Visual Genome dataset from English to Hindi. |
|
|
|
I borrowed this template from Jon Barron's website.
|